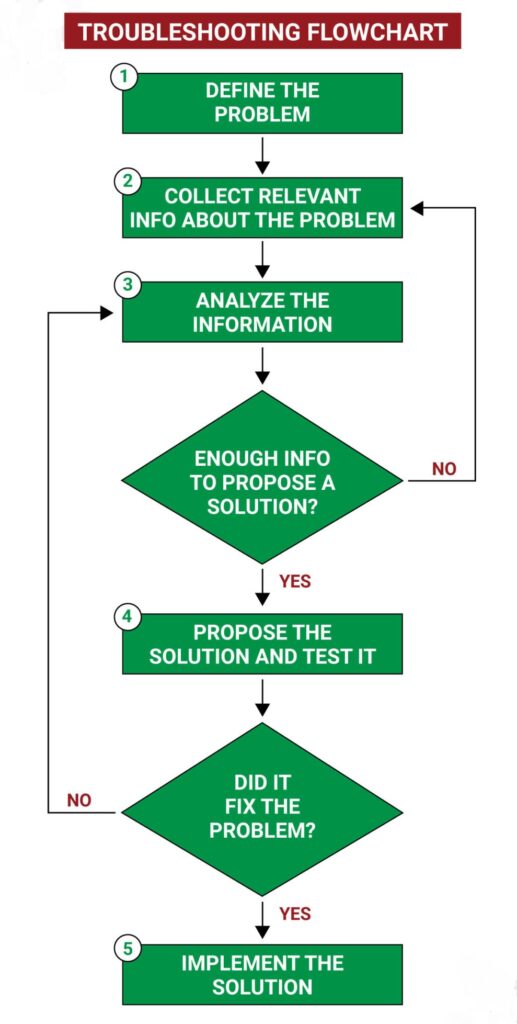
Here is the CompTIA fault finding or troubleshooting methodology as it is called by CompTIA

- Identify the problem
- Establish a theory of probable cause
- Test the theory to determine the cause
- Establish a plan of action to resolve the problem and identify potential effects
- Implement the solution or escalate as necessary
- Verify full system functionality and, if applicable, implement preventive measures
- Document findings, actions, outcomes and lessons learned
Let’s see what these steps entail.
1. Identify the Problem
This step is often the easiest. It may be accomplished via an inbound phone call from a user, a help desk ticket, an email message, a log file entry or any number of other sources. It is not at all uncommon for users to alert you to the problem or outage.
It’s important to recognize that the root cause of specific issues is not always apparent. For example, a failed login attempt might seem to indicate a username or password problem when instead, the real issue may be a lack of network connectivity that prevents the authentication information from being checked against a remote server.
As troubleshooters, we want to be very careful to ensure we have identified the root cause of the error, mis-configuration or service interruption before making any changes.
Specific steps here may include:
- Gathering information from log files and error messages
- Questioning users
- Identifying symptoms
- Determining recent changes
- Duplicating the problem
- Approaching multiple problems one at a time
- Narrowing the scope of the problem
2. Establish a Theory of Probable Cause
I’d like to start by pointing out the impreciseness of the words in this step. Words such as theory and probable indicate a guess on your part, even if it is a guess backed by data. The way this step is written acknowledges that the root cause (step one) may not have been accurately identified. However, the cause is specific enough to begin troubleshooting.
This stage may require significant research on your part. Vendor documentation, your organization’s own documentation and a good old-fashioned Google search may all be required to provide the basis for your theory. It’s a process of elimination.
Companies like Cisco, Red Hat, Microsoft and Apple maintain documentation and issue repositories and forums where troubleshooters exchange ideas and read about common causes, solutions and troubleshooting methods provided by other IT personnel. Similar knowledge bases exist for cyber security concerns.
The steps in this phase are:
- Questioning the obvious to identify the cause of the problem
- Considering multiple approaches, including top-to-bottom or bottom-to-top for layered technologies (such as networks)
One of the main issues that I’ve observed with newer troubleshooters is failing to question the obvious. In my classes, I rephrase this as “start simple and work toward the complex.” Yes, I am aware that operating systems, networks and cloud deployments are all very complex. However, that does not mean that your issue is complex. The possible causes may be far simpler than you assume.
I have found over the years that careful note-taking is important at this point. Your notes can include data copied from websites, web URLs, suggestions from your team members, etc.
3. Test the Theory to Determine the Cause
What’s most interesting about steps one and two is that they don’t require you to make configuration changes. They are about gathering information. You shouldn’t make changes until you are reasonably sure you have a solution you’re ready to implement.
This step is also part of the “information-gathering” phase.
It is not uncommon for experienced administrators to move very quickly and informally through steps one, two and three. Issues and symptoms are often based on common problems, making it simple to guess the likely cause of an error message or failed device.
At this stage, you may find yourself circling all the way back to step one, Identify the problem. If you test your theory to discover the likely cause and find that you were incorrect, you may need to start your research all over again. You can check in with users, dig deeper into log files, use Google, etc.
Some workstation troubleshooting will involve hardware components, such as the CPU, memory (RAM) and storage (solid state and hard disk drives). You may need to replace these pieces with known good parts. Other issues may be software-based, such as problems with the operating system (whether Windows, Linux or macOS) or with applications (Word, Excel, Chrome or other programs).
A network troubleshooting process differs from problem-solving on standalone workstations or servers. An effective network troubleshooting methodology for network problems begins with a solid understanding of the Open Systems Interconnection (OSI) model. This seven-layer model defines the networking process and is considered a fundamental concept.
Start by verifying the system’s IP address configuration. Next check the status of network components, such as routers and switches. Verify service availability, too. Network services like Domain Name Service (DNS), Dynamic Host Configuration Protocol (DHCP) and firewalls are all critical to network functionality. Tools such as Nmap and Wireshark can be helpful for troubleshooting.
Once you’re confident you’d found the fundamental issue, the next step is to prepare to solve the problem.
4. Establish a Plan of Action and Implement the Solution
If you believe you know the root cause of the troubleshooting issue, you can plan how to address it. Here are some reasons to plan ahead before blindly jumping into a given course of action:
- Some fixes require reboots or other more significant forms of downtime
- You may need to download software, patches, drivers or entire operating system files before proceeding
- Your change management procedures may require you to test modifications to a system’s configuration in a staging environment before implementing the fix in production
- You may need to document a series of complex steps, commands and scripts
- You may need to back up data that might be put at risk during the recovery
- You may need approval from other IT staff members before making changes
You can begin modifying the system’s configuration after this stage.
You’re now ready to do whatever you believe you need to do to solve the problem. These steps may include:
- Running your scripts
- Updating your systems or software
- Editing configuration files
- Changing firewall settings
Make sure that you have a rollback plan in place in case the fix you’re attempting does not address the issue. You must be able to reverse your settings to at least get back to where you began.
In some cases, implementing the proposed fix may be quicker than the research phases that preceded it. Those research phases are essential, however, to make sure you’re addressing the real issue and minimizing downtime.
5. Verify Full System Functionality and Implement Preventive Measures
I once observed a failure at this very stage of troubleshooting. A user called the support person in question to investigate a printer that wasn’t working. When he arrived, he noticed the printer power cord was unplugged. He plugged it back in, grumbled about users not understanding computers, and walked away. What he failed to realize, however, was that the printer was jammed and that the users had unplugged it while attempting to fix the jam. The tech walked away without verifying functionality.
Have the users that rely on the system test functionality for you when possible. They are the ones that really know how the system is supposed to act and they can ensure that it responds to their specific requirements.
Depending on the problem, you may need to apply the fix to multiple servers or network devices. For example, if you’ve discovered a problem with a device driver on a server, you may need to update the drivers on several servers that rely on the same device.
6. Document Findings
Documentation is a pet peeve of mine. It comes from working as a network administrator for an organization with zero documentation. I was the sixth administrator the company had hired in five years, and no one before me wrote down anything. It was a nightmare.
Documenting your troubleshooting steps, changes, updates, theories and research could all be useful in the future when a similar problem arises (or when the same problem turns out not to have been fixed after all).
Another reason to keep good documentation as you go through the entire methodology is to communicate to others what you have tried so far. I was on the phone once with Microsoft tech support for a failed Exchange server. The first thing the tech said was, “What have you tried so far?” I had a three-page list of things we didn’t need to try again. This systematic approach saved us a lot of time.
Such documentation is also useful in case your changes have unintended consequences. You can more easily reverse your changes or change configurations if you have good documentation on exactly what you did.
7. Keep It Simple
This troubleshooting methodology is just a guide, however. Each network environment is unique, and as you gain experience in that environment, you’ll more easily be able to predict the likely causes of issues and apply the correct troubleshooting techniques.
If I could pass on one bit of wisdom to future support staff members, it would be the tidbit above regarding starting simple to identify potential causes. In my courses one of the main troubleshooting checklists I suggested was this:
- Is it plugged in?
- Is it on?
- Did you restart it?
That may seem facetious and over-simplified, but those steps are actually worthwhile (in fact, it’s useful to double-check those steps). However, the real lesson is not those three steps but rather the spirit of those tasks, which is to start simple and work toward the more complex.
Finally, one thing the troubleshooting methodology above does not address is time. In many cases, you will be working within the confines of service level agreements (SLA), regulatory restrictions or security requirements. In those situations, you must be able to accomplish the above steps efficiently.
Being deliberate about following a troubleshooting methodology can make you much more consistent and efficient at finding and resolving system and network issues. I strongly encourage you to formalize such a methodology for your support staff.